从零搭建 Claude Code 团队遥测监控 -- Windows 原生服务 + Prometheus + Grafana 实战
不用 Docker,在一台 Windows 服务器上跑通 OpenTelemetry 全链路,附 11 个真实踩坑记录
一、背景与目标
Claude Code 内置 OpenTelemetry(OTel)支持,只要打开开关并配置导出端点,就能把使用数据以 指标(metrics) 和 事件(events/logs) 两种信号导出。我们的目标很朴素:
- 按用户、部门维度统计;
- 关注会话数、提交数、代码行、编辑决策、Token 消耗、活跃时长、事件数;
- 做成一张能排序、能筛选的 Grafana 看板;
- 数据保留约一年,方便回看。
约束条件:遥测后端要部署在一台独立的 Windows 服务器上,且不能用 Docker(合规/环境限制),全部以 Windows 原生服务运行。
二、整体架构
每个开发者的 Claude Code
│ OTLP / gRPC :4317
▼
OTel Collector(中心服务器)
│ 暴露 :8889/metrics
▼
Prometheus(抓取,保留 400 天)
│
▼
Grafana(看板)
关键点:团队场景不能让 Prometheus 去抓每个人的笔记本(地址不固定、网络不通),所以中间用 Collector 做集中接收——客户端主动 push 到 Collector,Prometheus 只抓 Collector 一个固定地址。
三、服务端搭建(Windows 原生服务)
3.1 组件选型与下载
| 组件 | 安装方式 | 说明 |
|---|---|---|
| OTel Collector | MSI | 选 otelcol-contrib(contrib 版才有 prometheus exporter 和 count 连接器),架构选 x64 |
| Grafana | MSI | OSS 版,装完自动注册服务 |
| Prometheus | zip + NSSM | 官方没有 MSI,需用 NSSM 把 exe 注册成 Windows 服务 |
小坑预告:OTel Collector 的 MSI 文件名是
otelcol-contrib_x.y.z_windows_**x64**.msi,而压缩包才叫amd64。x64 = amd64,别因为找不到 “amd64.msi” 而懵。
3.2 OTel Collector
MSI 装完后服务名 otelcol-contrib,配置文件在 C:\Program Files\OpenTelemetry Collector\config.yaml。核心配置:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
transform/promote_user: # 把资源属性 user_name/department 搬到日志,供事件计数使用
log_statements:
- context: log
statements:
- set(attributes["user_name"], resource.attributes["user_name"]) where resource.attributes["user_name"] != nil
- set(attributes["department"], resource.attributes["department"]) where resource.attributes["department"] != nil
connectors:
count: # 把"事件"按 event.name 转成可统计的指标
logs:
claude_code.events:
conditions:
- 'attributes["event.name"] != nil'
attributes:
- key: event.name
default_value: unknown
- key: user_name
default_value: unknown
- key: department
default_value: unknown
exporters:
prometheus:
endpoint: 0.0.0.0:8889
resource_to_telemetry_conversion:
enabled: true # 让 OTEL_RESOURCE_ATTRIBUTES 变成指标标签
service:
pipelines:
metrics:
receivers: [otlp, count]
processors: [batch]
exporters: [prometheus]
logs:
receivers: [otlp]
processors: [transform/promote_user]
exporters: [count]
改完 Restart-Service otelcol-contrib。
为什么要 count 连接器?因为提示数、API 请求、工具调用等都是"事件",不是指标。指标里根本没有"提示数"这个计数器。要统计事件次数,必须开 logs 管道,用 count 连接器把事件转成指标。
3.3 Prometheus(含保留期)
解压后用 NSSM 注册服务,并把保留期设为 400 天(覆盖约一年):
$nssm = "C:\telemetry\nssm\win64\nssm.exe"
$prom = "C:\telemetry\prometheus"
& $nssm install prometheus "$prom\prometheus.exe" "--config.file=$prom\prometheus.yml" "--storage.tsdb.path=$prom\data" "--storage.tsdb.retention.time=400d"
& $nssm set prometheus AppDirectory "$prom"
& $nssm start prometheus
prometheus.yml 只需抓 Collector 一个目标:
global:
scrape_interval: 30s
scrape_configs:
- job_name: claude-code
static_configs:
- targets: ["localhost:8889"]
3.4 Grafana 与防火墙
Grafana 用 MSI 装,服务名 Grafana,默认 :3000,加 Prometheus 数据源(http://localhost:9090)即可。
防火墙只需对外开放两个端口:4317(客户端上报)和 3000(看板访问)。8889、9090 仅本机内部使用,不必对外。
四、客户端配置(团队下发)
每个成员编辑 %USERPROFILE%\.claude\settings.json,填服务器地址和自己的身份:
{
"env": {
"CLAUDE_CODE_ENABLE_TELEMETRY": "1",
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_PROTOCOL": "grpc",
"OTEL_EXPORTER_OTLP_ENDPOINT": "http://<服务器IP>:4317",
"OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE": "cumulative",
"OTEL_RESOURCE_ATTRIBUTES": "user_name=ZhangSan,department=FrontEnd"
}
}
cumulative 那行别漏:Prometheus 需要累计型计数器,而 Claude Code 默认是 delta。
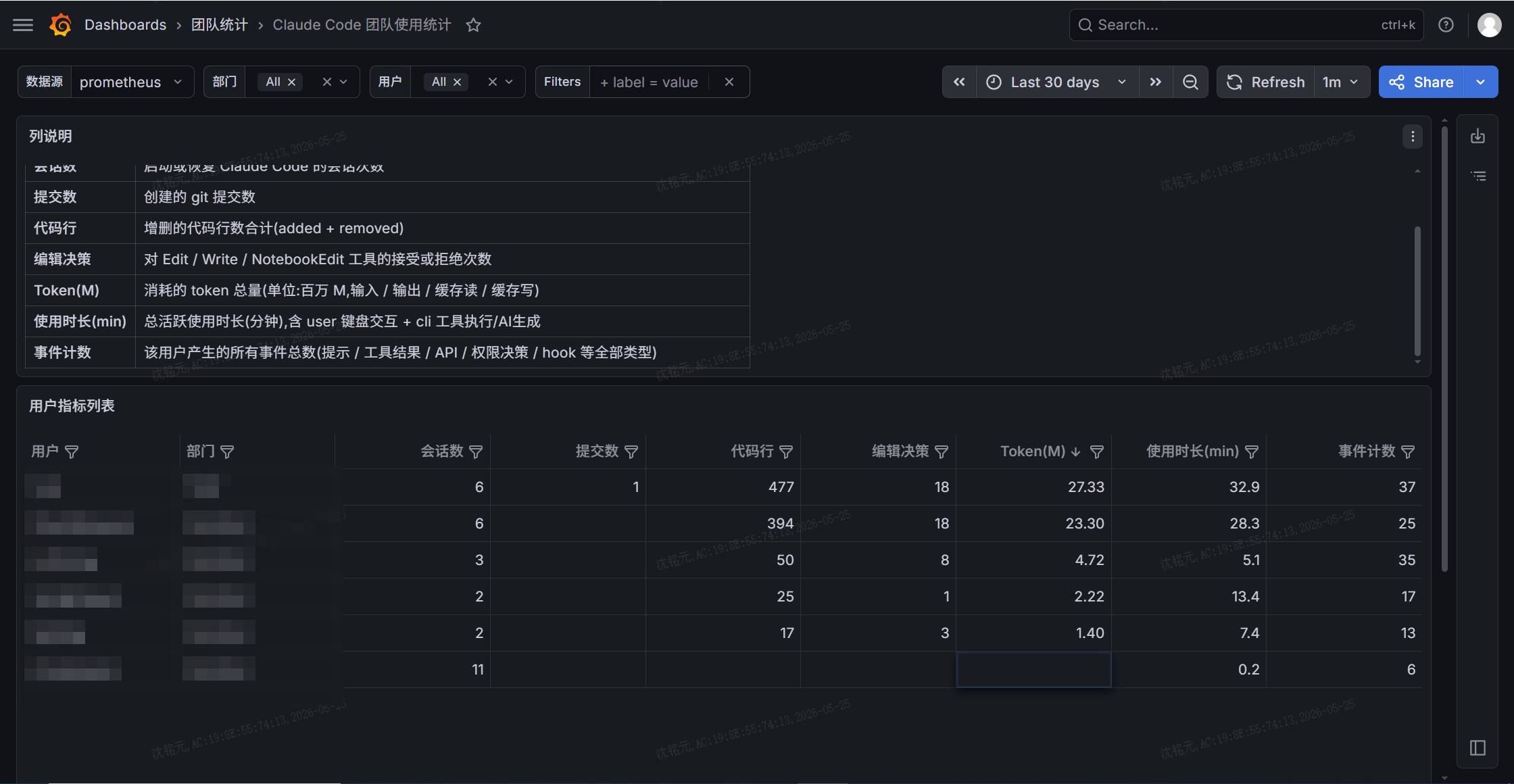
五、看板设计
最终落到一张表:用户 / 部门 / 会话数 / 提交数 / 代码行 / 编辑决策 / Token(M) / 使用时长(min) / 事件计数,可点列头排序、按部门/用户筛选,每列带说明。
由于这些计数器的特殊性(见下文踩坑),查询统一采用:
sum by (user_name, department) (max_over_time(<metric>[$__range]))
六、踩坑实录(本文精华)
-
MSI 叫 x64 不叫 amd64——Collector 的 MSI 用
windows_x64,tar.gz 才用amd64,同一架构不同叫法。 -
Prometheus 没有官方 MSI——只能 zip + NSSM。搜到的
windows_exporter.msi是另一个东西(采集主机指标),别装错。 -
console 导出器在 TUI 里看不到——
OTEL_METRICS_EXPORTER=console的输出会被交互界面吞掉,验证本机请改用prometheus导出器看http://localhost:9464/metrics。 -
指标名带单位后缀——经 Collector 导出后,名字不是文档里的样子:
claude_code_token_usage_**tokens**_totalclaude_code_active_time_**seconds**_totalclaude_code_cost_usage_**USD**_total- 而
claude_code_code_edit_tool_decision_total(单位是 count)却没有 count 后缀。 规律不一致,务必查实际库里的真名,别照文档猜。
-
increase()对"一次性计数器"返回 0——session_count每个会话是一条恒为 1 的序列,increase()看不到增长,算出来永远是 0。改用count(count_over_time(...))或max_over_time求和。 -
提示数/事件数是"事件"不是"指标"——必须开 logs 管道 + count 连接器才能统计(见 3.2)。
-
用户名/部门要靠资源属性——客户端设
OTEL_RESOURCE_ATTRIBUTES,服务端开resource_to_telemetry_conversion,二者缺一不可。 -
资源属性不一定传到日志——某些版本
OTEL_RESOURCE_ATTRIBUTES不进 logs(只进 metrics),所以事件计数里用transform处理器手动把它"搬"到日志记录上。 -
代理(Clash/V2Ray)会拦截 OTLP——这是团队铺开时最隐蔽的坑。成员配了
HTTP_PROXY=127.0.0.1:7890,Claude Code 的 OTLP 导出会走代理去连内网地址,代理转发不到 → 数据全丢。Test-NetConnection还显示通(它直连不走代理),极具迷惑性。解法:加NO_PROXY和no_proxy(两种大小写都要,gRPC 库认小写)把服务器 IP 排除。 -
JSON 重复键 / 尾逗号——成员的 settings.json 里出现了两个
OTEL_METRICS_EXPORTER(后者prometheus覆盖了otlp),导致指标发到了本地而非服务器;尾随逗号则会让整个文件解析失败、配置全部失效。 -
Git Bash 家目录错位 + Grafana 权限——在 Git Bash/mintty 里跑
claude,读的是该环境的~/.claude,可能和 Windows 的%USERPROFILE%\.claude不是同一个文件(看terminal_type=mintty标签可识别)。另外,新版 Grafana 的 Viewer 角色默认看不到看板,需要在文件夹或看板上显式授予 View 权限。
七、总结
整套链路本身不复杂——难的全在细节:指标名、计数器语义、网络代理、配置文件位置。如果让我提炼三条经验:
- 别照文档猜指标名,直接查 Prometheus 里的真名(
group by (__name__)(...)); - 计数器统计优先用
max_over_time求和,避开increase()在低数据量下归零的陷阱; - 团队铺开时,代理是头号杀手,配置说明里务必写明
NO_PROXY。
最终,我们用一台 Windows 服务器、四个原生服务、一张看板,就让团队的 Claude Code 使用情况变得一目了然。可观测性的价值,正在于把"感觉大家在用"变成"看得见用了多少"。